本文共 4784 字,大约阅读时间需要 15 分钟。
序言
有些鸟,觉得理论没用.我觉得有用.通过理论会去发现它有哪些功能点,并且去搜索对应的问题点,可以事半功倍.在分析问题的时候也能很好的帮助你.
参考地址:
- 基本索引:
- 高级索引:
- 全文检索:
MongoDB的概念
MongoDB与传统数据库的概念对比
| SQL术语/概念 | MongoDB术语/概念 | 解释/说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
| index | index | 索引 |
| table joins | 表连接,MongoDB不支持 (使用文档的字段内嵌一个文档的形式, 但是复杂查询不好使) | |
| primary key | primary key | 主键,MongoDB自动将_id字段设置为主键 |
| RDBMS | MongoDB |
|---|---|
| 数据库 | 数据库 |
| 表格 | 集合 |
| 行 | 文档 |
| 列 | 字段 |
| 表联合 | 嵌入文档 |
| 主键 | 主键 (MongoDB 提供了 key 为 _id ) |
| 数据库服务和客户端 | |
| Mysqld/Oracle | mongod |
| mysql/sqlplus | mongo |
文档(Document)
文档是一组键值(key-value)对(即 BSON)。MongoDB 的文档不需要设置相同的字段(每个文档的字段数量可以不一样),并且相同的字段不需要相同的数据类型,这与关系型数据库有很大的区别,也是 MongoDB 非常突出的特点。
需要注意的是:
- 文档中的键/值对是有序的。
- 文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个嵌入的文档)。
- MongoDB区分类型和大小写。
- MongoDB的文档不能有重复的键。
- 文档的键是字符串。除了少数例外情况,键可以使用任意UTF-8字符。
文档键命名规范:
- 键不能含有\0 (空字符)。这个字符用来表示键的结尾。
- .和$有特别的意义,只有在特定环境下才能使用。
- 以下划线"_"开头的键是保留的(不是严格要求的)。
- MongoDB 中存储的文档必须有一个 _id 键。这个键的值可以是任何类型的,默认是个 ObjectId 对象由于 ObjectId 中保存了创建的时间戳,所以你不需要为你的文档保存时间戳字段,你可以通过 getTimestamp 函数来获取文档的创建时间
MongoDB的数据类型
| 数据类型 | 描述 |
|---|---|
| String | 字符串。存储数据常用的数据类型。在 MongoDB 中,UTF-8 编码的字符串才是合法的。 |
| Integer | 整型数值。用于存储数值。根据你所采用的服务器,可分为 32 位或 64 位。 |
| Boolean | 布尔值。用于存储布尔值(真/假)。 |
| Double | 双精度浮点值。用于存储浮点值。 |
| Min/Max keys | 将一个值与 BSON(二进制的 JSON)元素的最低值和最高值相对比。 |
| Array | 用于将数组或列表或多个值存储为一个键。 |
| Timestamp | 时间戳。记录文档修改或添加的具体时间。 |
| Object | 用于内嵌文档。 |
| Null | 用于创建空值。 |
| Symbol | 符号。该数据类型基本上等同于字符串类型,但不同的是,它一般用于采用特殊符号类型的语言。 |
| Date | 日期时间。用 UNIX 时间格式来存储当前日期或时间。你可以指定自己的日期时间:创建 Date 对象,传入年月日信息。 |
| Object ID | 对象 ID。用于创建文档的 ID。 |
| Binary Data | 二进制数据。用于存储二进制数据。 |
| Code | 代码类型。用于在文档中存储 JavaScript 代码。 |
| Regular expression | 正则表达式类型。用于存储正则表达式。 |
ObjectId
ObjectId 类似唯一主键,可以很快的去生成和排序,包含 12 bytes,含义是:
- 前 4 个字节表示创建 unix 时间戳,格林尼治时间 UTC 时间,比北京时间晚了 8 个小时
- 接下来的 3 个字节是机器标识码
- 紧接的两个字节由进程 id 组成 PID
- 最后三个字节是随机数

mongodb的事务与隔离级别
下面说一说MongoDB的事务支持,这里可能会有疑惑,前面我们在介绍MongoDB时,说MongoDB是一个NoSQL数据库,不支持事务。这里又介绍MongoDB的事务。这里要说明一下MongoDB的事务支持跟关系型数据库的事务支持是两码事,如果你已经非常了解关系型数据库的事务,通过下面一副图对比MongoDB事务跟MySQL事务的不同之处。
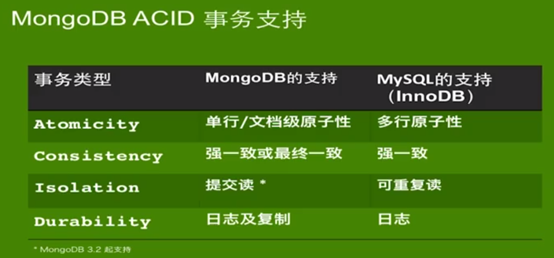
MongoDB对原子性(Atomicity)的支持
Mongodb的原子性是单行/文档级原子性,即仅仅支持一个文档的所有字段的全部更新,如果其中一个字段更新失败了,就会回滚.
如果是一次批量更新10条数据,如果第5条失败了,则前4个文档都不会回滚,仅仅第五个文档会回滚.
MongoDB对一致性(consistency)的支持
最终一致性,如果传统数据库也是集群的也是最终一致性.这个参考CAP理论没什么好说的.
MongoDB对隔离性(isolation)的支持(这个很重要)
在关系型数据库中,SQL2定义了四种隔离级别,分别是READ UNCOMMITTED、READ COMMITTED、REPEATABLE READ和SERIALIZABLE。
但是很少有数据库厂商遵循这些标准,比如Oracle数据库就不支持READ UNCOMMITTED和REPEATABLE READ隔离级别。而MySQL支持这全部4种隔离级别。每一种级别都规定了一个事务中所做的修改,哪些在事务内核事务外是可见的,哪些是不可见的。
为了尽可能减少事务间的影响,事务隔离级别越高安全性越好但是并发就越差;事务隔离级别越低,事务请求的锁越少,或者保持锁的时间就越短,这也就是为什么绝大多数数据库系统默认的事务隔离级别是RC。
下图展示了几家不同的数据库厂商的不同事物隔离级别

MongoDB在3.2之前使用的是“读未提交”,这种情况下会出现“脏读”。但在MongoDB 3.2开始已经调整为“读已提交”。
- READ-UNCOMMITTED(读尚未提交的数据):在这个级别,一个事务的修改,即使没有提交,对其他事务也都是可见的。事务可以读取未提交的数据,这也被称为“脏读(dirty read)”。这个级别会导致很多问题,从性能上来说,READ UNCOMMITTED不会比其他的级别好太多,但却缺乏其他级别的很多好处,除非真的有非常必要的理由,在实际应用中一般很少使用。
- READ-COMMITTED(读已提交的数据):在这个级别,能满足前面提到的隔离性的简单定义:一个事务开始时,只能“看见”已经提交的事务所做的修改。换句话说,一个事务从开始直到提交之前,所做的任何修改对其他事务都是不可见的。这个级别有时候也叫“不可重复读(non-repeatable read)”,因为两次执行同样的查询,可能会得到不一样的结果。
- REPEATABLE-READ(可重复读):在这个级别,保证了在同一个事务中多次读取统一记录的结果是一致的。MySQL默认使用这个级别。InnoDB和XtraDB存储引擎通过多版本并发控制MVCC(multiversion concurrency control)解决了“幻读”和“不可重复读”的问题。通过前面的学习我们知道RR级别总是读取事务开始那一刻的快照信息,也就是说这些数据数据库当前状态,这在一些对于数据的时效特别敏感的业务中,就很可能会出问题。
- SERIALIZABLE(串行化):在这个级别,它通过强制事务串行执行,避免了前面说的一系列问题。简单来说,SERIALIZABLE会在读取的每一行数据上都加锁,所以可能导致大量的超时和锁争用的问题。实际应用中也很少在本地事务中使用SERIALIABLE隔离级别,主要应用在InnoDB存储引擎的分布式事务中。
MongoDB对持久性(durability)的支持

MongoDB同样是使用数据进来先写日志(日志刷盘的速度是非常快)然后在写入到数据库中的这种方式来保证数据的持久性,(说明关系型数据库和MongoDb都是先写入日志,然后在同步到数据库文件中的.)
如果出现服务器宕机,当启动服务器时会从日志中读取数据。不同的是传统数据库这种方式叫做“WAL” Write-Ahead Logging(预写日志系统),而MongoDB叫做“journal”。此外MongoDB在数据持久性上这点可能做的更好,MongoDB的复制默认节点就是三节点以上的复制集群,当数据到达主节点之后会马上同步到从节点上去。
MongoDB的索引(Hbase只有有主键索引,Mongodb则可以有多个,还挺丰富)
- 基本索引:
- 高级索引:
- 全文检索:
网络上的一些描述
实用性
MongoDB是一个面向文档的数据库,它并不是关系型数据库,直接存取BSON,这意味着MongoDB更加灵活,因为可以在文档中直接插入数组之类的复杂数据类型,并且文档的key和value不是固定的数据类型和大小,所以开发者在使用MongoDB时无须预定义关系型数据库中的”表”等数据库对象,设计数据库将变得非常方便,可以大大地提升开发进度(不是说不用设计表,而变的方便.而是其灵活的结构)。
可用性和负载均衡(副本集的部署方式实现)
MongoDB在高可用和读负载均衡上的实现非常简洁和友好,MongoDB自带了副本集的概念,通过设计适合自己业务的副本集和驱动程序,可以非常有效和方便地实现高可用,读负载均衡。而在其他数据库产品中想实现以上功能,往往需要额外安装复杂的中间件,大大提升了系统复杂度,故障排查难度和运维成本。(高可用性使用它的副本集的部署方式,具体参考:)
扩展性(分片部署的方式实现)
在扩展性方面,假设应用数据增长非常迅猛的话,通过不断地添加磁盘容量和内存容量往往是不现实的,而手工的分库分表又会带来非常繁重的工作量和技术复杂度。在扩展性上,MongoDB有非常有效的,现成的解决方案。通过自带的Mongos集群,只需要在适当的时候继续添加Mongo分片,就可以实现程序段自动水平扩展和路由,一方面缓解单个节点的读写压力,另外一方面可有效地均衡磁盘容量的使用情况。整个mongos集群对应用层完全透明,并可完美地做到各个Mongos集群组件的高可用性。
数据压缩(压缩后造成的问题显而易见,查询速度慢)
自从MongoDB 3.0推出以后,MongoDB引入了一个高性能的存储引擎WiredTiger,并且它在数据压缩性能上得到了极大的提升,跟之前的MMAP引擎相比,压缩比至少可增加5倍以上,可以极大地改善磁盘空间使用率。
其他特性(适合做日志数据库,可以重点关注下)
相比其他关系型数据库,MongoDB引入了”固定集合”的概念。所谓固定集合,就是指整个集合的大小是预先定义并固定的,内部就是一个循环队列,假如集合满了,MongoDB后台会自动去清理旧数据,并且由于每次都是写入固定空间,可大大地提升写入速度。这个特性就非常适用于日志型应用,不用再去纠结日志疯狂增长的清理措施和写入效率问题。另外需要更加精细的淘汰策略设置,还可以使用TTL索引(time-to-liveindex),即具有生命周期的索引,它允许为每条记录设置一个过期时间,当某条记录达到它的设置条件时可被自动删除。
MongoDB不适用的应用场景
- MongoDB不支持事务操作,所以需要用到事务的应用建议不用MongoDB,另外
- MongoDB目前不支持join操作,需要复杂查询的应用也不建议使用MongoDB。
转载地址:http://abcmf.baihongyu.com/